
AI search, personalized recommendations, and shopping agents are becoming standard ambitions for online stores, and for good reason: Effective Upselling: +30% Profit Using Magento & AEMPersonalized product recommendations are key to effective cross- and upselling. Read how Magento and Adobe AEM enable full-funnel strategies.personalization can drive a 20% uplift in sales, and according to Salesforce, AI-powered product recommendations can deliver a 26% higher average order value (AOV).
So why do many of these AI features still feel underwhelming when it comes to product discovery? If you have come across “smart” search that returns irrelevant results, engines that recommend items customers already bought, or chat assistants that fail to match a product phrased slightly differently, you are not the only one.
And the tool itself is rarely the main culprit. What's usually holding performance back is the data it depends on, specifically, the product data architecture underneath it.
If attributes are incomplete, taxonomy is inconsistent, or behavioral data is disconnected, AI features lack the support they need for accurate retrieval, ranking, and matching. The bigger the catalog and the more teams involved in maintaining it, the harder these issues become to manage consistently.
This article explains what AI-ready catalog structure actually looks like, where the common failure points are, and how to assess your current setup, alongside platform-specific guidance for Magento and Shopify.
TMO Group's eCommerce AI Agent Solutions start with a diagnostic mapping of your current workflows and data readiness before AI implementation begins.
1. What is Catalog Data Architecture?
Catalog data architecture is the structural framework that controls how product data is organized, labeled, and connected across your eCommerce system. It has five dimensions:
| Dimension | Description | Relevance |
|---|---|---|
| Category Hierarchy | How products are grouped and nested in the navigation tree | The primary structural signal AI uses to infer product context and relationships |
| Attribute Sets | The defined fields for each product type: naming conventions, formats, and required values (e.g., Magento Attribute Sets) | Drives which facets are available for filtering; inconsistencies break semantic mapping |
| Enumerated Values | Controlled vocabularies for filterable fields: the fixed options within an attribute (e.g., finish options: Silk Matt, Gloss, Matte) | Non-standardized values are treated as distinct entities by AI; synonyms go unrecognized |
| Variant / Configurable Logic | How configurable products relate to child SKUs; size/color inheritance | Variants not properly linked to their parent product fragment behavioral signals and degrade recommendation accuracy |
| Metadata & Semantic Layer | Titles, tags, synonyms, and descriptions that carry linguistic context | The core input for NLP-based AI search; thin metadata means thin, inaccurate results |
With traditional keyword search, messy catalog data is often workable. Shoppers may still find products through obvious term matches, and teams can patch missing tags or metadata over time.
AI-driven systems are less forgiving. Search models, recommendation engines, and shopping agents do not just look for matching words. They try to interpret intent, map it to structured product attributes, and rank the most relevant results.
Take a query like “matte wood-grain tile.” To return the right result, the system needs to recognize multiple dimensions at once: product type, surface finish, and visual style. That only works when those dimensions are modeled consistently in the catalog. If they are missing, uneven, or disconnected, the system has much weaker signals to work with.
As a result, the consequences of bad data are amplified: AI systems rely on catalog structure to interpret products, match intent, and rank results. If that structure is inconsistent, the output becomes systematically less reliable.
2. Common Issues for Product Data Structure
Here are the four catalog problems that most consistently undermine AI performance in eCommerce operations.
Inconsistent Attribute Naming
Common in any established brand as operation scales, the same attribute accumulates multiple names over time. For example, a style field might hold Nordic, Minimalist Nordic, and Nordic Style with no standardized mapping between them.
- Issue: Semantic matching breaks because the model can't reliably consolidate these variants. Filters also fracture, as "Nordic" and "Nordic Style" register as separate facet values, and recommendation models miss product affinity that would be obvious to a human.
- Outcome: Zero-result rates climb, and shoppers who hit empty or irrelevant filter results often leave.
Missing or Incomplete Field Data
Many catalogs have a workable attribute structure in theory. The fields exist, they're just not filled in: truncated titles, blank descriptions, or missing material, dimension, finish, or compatibility attributes across large swaths of the SKU range.
- Issue: Sparse training data produces weak product associations, and models can't learn what defines a category when half the entries are empty.
- Outcome: AI recommendations cluster around a handful of high-traffic SKUs. As a result, long-tail inventory or new product launches underperform because AI can't connect them to relevant audiences.
Category Hierarchy Organized for the Business, Not the Customer
Category trees tend to mirror how a company runs internally: organized by supplier, SKU code, or warehouse logic rather than how customers actually shop. A building materials brand might sort tiles by format (30×30, 60×60, large slab) while buyers search by room type, style, or surface application.
- Issue: Category hierarchy is a core structural signal AI uses to understand product context. A hierarchy built on internal logic teaches AI the wrong relationships between products and categories.
- Outcome: AI-powered navigation serves products in the wrong context. Cross-sell and upsell logic fails because the system can't identify genuinely complementary products from an operations-first taxonomy.
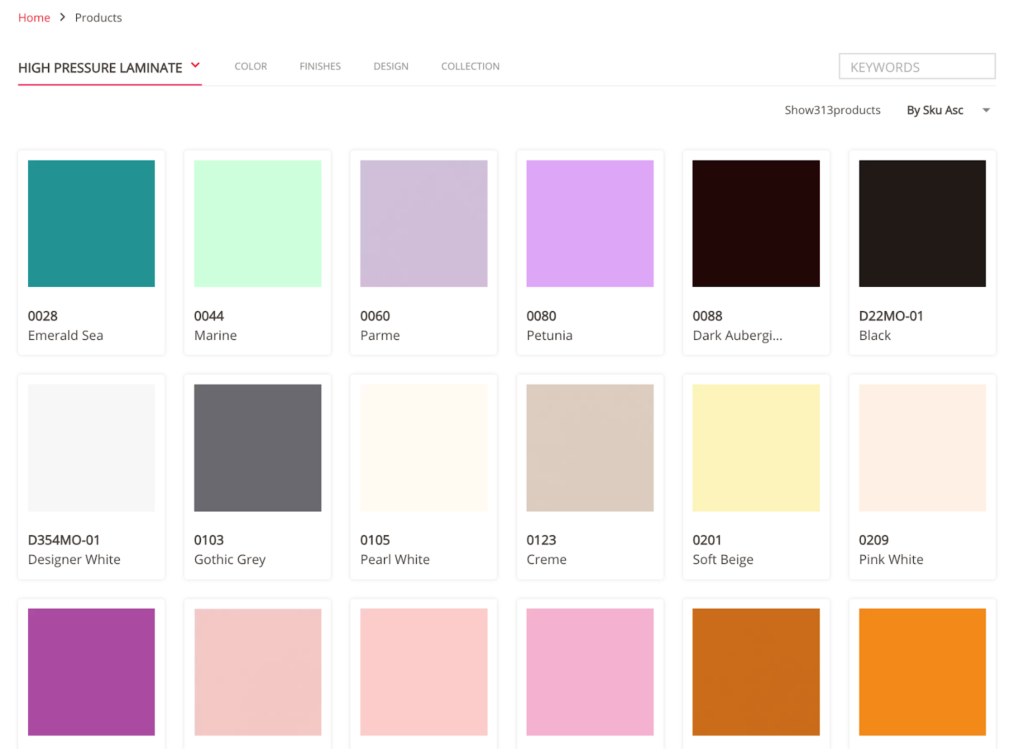
Wilsonart's categorization of architectural finishes allows users to quickly narrow searches by color, material, texture and more.
Behavioral Data and Catalog Data Operating in Silos
Well-functioning AI eCommerce works as a learning loop:
- catalog structure sets the initial framework
- user behavior (clicks, dwell time, add-to-cart, purchase) refines the model
- better models produce better results
- better results generate richer behavioral data.
- Issue: That loop only closes when behavioral data and product data are connected. In practice, they often aren't: analytics tools hold behavioral data, ERP or PIM systems hold product data, and no shared identifier links the two. Without that connection, AI can't learn.
- Outcome: AI ROI plateaus rather than compounds. Traffic growth doesn't make the system smarter because the learning loop was never completed.
3. Assessing your Catalog's AI Readiness
Use this framework to gauge catalog readiness before committing to AI eCommerce initiative. This can help surface the structural issues most likely to limit AI performance. How to Use:
First, score each dimension as "Ready", "Needs Improvement", or "Critical Gap"
| Dimension | What to Assess | Warning Signs |
|---|---|---|
| 1. Attribute Standardization | Are attribute names and enumerated values consistent across the full catalog? Is data entry governed by controlled vocabularies? | Multiple expressions for the same concept; attributes maintained by different teams with no shared standard |
| 2. Field Completeness | What's the fill rate for core filterable and searchable attributes? Are required fields enforced? | Attributes critical to AI search are set as optional; large portions of the catalog have blank fields |
| 3. Category Tree Design | Does your hierarchy reflect how customers discover products? | Categories use internal codes or warehouse labels; structure doesn't map to how customers actually search |
| 4. Variant & Configurable Logic | Are product variants (size, color, finish, material) correctly mapped as child SKUs with clear parent inheritance? | Variants exist as standalone simple products with no parent-child relationship |
| 5. Metadata & Semantic Layer | Do product titles, tags, and descriptions carry the semantic content AI needs: synonyms, use cases, material descriptors, application language? | Titles are model numbers or SKU codes; tag fields are empty or filled inconsistently |
Next: rate your results:
- Two or more Critical Gaps: AI tools will almost certainly underperform until these are fixed.
- Three or more Needs Improvement: This is where most scaled catalogs sit. Targeted remediation delivers measurable gains quickly.

4. Implementing AI Product Discovery (Magento / Shopify)
While the same catalog principles apply regardless of your platform, implementation can differ slightly:
Shopify
Shopify's AI capabilities depend on structured product data more than most merchants realize:
- Shopify Magic: The output of AI-generated product descriptions is capped by the attribute data fed in. Sparse or inconsistent fields can produce generic, low-converting copy.
- Metafields: The data layer that enables fine-grained personalization in AI recommendation apps like Rebuy, LimeSpot, and Wiser. Underutilizing Metafields limits what any recommendation app can do.
- AI Search Plugins (Algolia, Klevu, Boost AI Search): All rely on NLP semantic matching. Relevance quality is directly tied to how semantically rich your product titles, tags, and descriptions are.
Algolia AI Search Plugin
Before you install anything: Audit Metafield coverage, and check that titles, tags, and descriptions for your core categories have enough semantic depth for NLP to work with.
Magento / Adobe Commerce
Similarly, Adobe Commerce's native AI features (Live Search, Product Recommendations, and Merchandising AI) are only as good as the catalog structure supporting them.
| Adobe Commerce Feature | Data Dependency | Impact of Poor Catalog Structure |
|---|---|---|
| Live Search | Product titles, descriptions, and structured attribute data | Unstandardized Attribute Sets degrade the engine's understanding of product characteristics, and results become less relevant, filters less precise |
| Product Recommendations | Behavioral data and product metadata | Incomplete attributes allow the engine to run on behavior alone, but cold-start accuracy, similarity matching, and precision recommendations all suffer, so the system defaults to generic trending logic |
| Attribute Sets | Define the entire product data schema — the foundation everything else is built on | Non-standardized Attribute Sets are one of the most common root cause of AI underperformance across Magento deployments |
Before you activate any Adobe Commerce AI feature: Run an Attribute Sets audit and normalize your enumerated values.
5. 3 Phases to Improve your Catalog Structure
You don't need a full-catalog overhaul to start seeing results! A phased approach, prioritized by commercial impact, is faster to execute and delivers earlier wins.
Phase 1: Establish Governance Standards
Fix the rules before you touch the data:
- Define controlled vocabularies for all filterable attributes in core categories
- Set naming conventions and enforce mandatory field requirements
- Map existing attribute values to the new standardized vocabulary
- Identify and correct category hierarchy misalignments in your highest-traffic segments
Phase 2: Execute Remediation
Work through the catalog in revenue-first order:
- Start with your top 20% of SKUs by traffic and revenue
- Combine manual review with AI-assisted tooling to fill missing attribute values
- Restructure category hierarchies using real user intent data (search queries, navigation heatmaps)
- Build synonym libraries and semantic tag systems within the remediated product set
Phase 3: Integration and Learning Loop
Close the loop between your catalog and your AI systems:
- Connect standardized catalog data to your AI search and recommendation platforms
- Set up monitoring that links user behavior to specific products and attributes
- Establish data governance standards for new product onboarding so quality is maintained going forward
- Track what matters: zero-result rate, search refinement rate, recommendation click-through rate
Your product catalog is the interface between your inventory and how customers find it. Its quality sets the ceiling on what AI can deliver.
Building AI-Ready Commerce Stacks with TMO
You don't need an AI tool shortlist to begin. Start with two quick diagnostics:
- Pull 100 SKUs from your highest-revenue categories and score them against the five-dimension framework above.
- Check your site's zero-result search rate. Above 5% is a warning sign. Above 10% needs immediate attention.
For teams ready to move systematically, TMO Group offers AI-Ready Commerce Stack Design for mid-to-large ecommerce brands:
- Product catalog structure and attribute standardization
- Event tracking architecture
- ERP and CRM integration
- Behavioral data pipelines
This technical foundation is what makes AI search, recommendations, dynamic pricing, and intelligent operations actually deliver.
Talk to TMO about assessing your catalog readiness, strengthening your product data foundation, or planning AI-driven commerce implementations.
FAQ
Product data architecture or catalog structure is the framework that organizes your product data, including category hierarchy, attributes, values, variant logic, and metadata. Because AI search and recommendation systems interpret intent rather than match keywords, their accuracy is directly constrained by how clean and consistent your underlying catalog data is.
Start with two quick checks: your on-site zero-result search rate (above 5% signals a problem; above 10% requires urgent action), and a spot-check of 100 high-revenue SKUs against the five-dimension framework above. Three or more Critical Gap scores means you should remediate before deploying AI.
It doesn't require a freeze. A three-phase approach (governance, remediation, integration) is designed to deliver incremental improvements at each stage. Most teams see measurable impact on search and recommendation performance within 60–90 days of starting Phase 1.
It's not too late, it's the most valuable thing you can do now. A messy catalog doesn't just limit initial performance; it actively degrades AI models over time by feeding them low-quality behavioral signals.
Always run the catalog diagnostic first. Your data structure determines which tools are a realistic fit, what integration work is actually required, and what performance you can reasonably expect.